Inner product argument
What is an inner product argument?
The inner product argument is the following construction: given the commitments (for now let’s say the hash) of two vectors and of size and with entries in some field , prove that their inner product is equal to .
There exist different variants of this inner product argument. In some versions, none of the values (, and ) are given, only commitments. In some other version, which is interesting to us and that I will explain here, only is unknown.
How is that useful?
Inner products arguments are useful for several things, but what we’re using them for in Mina is polynomial commitments. The rest of this post won’t make too much sense if you don’t know what a polynomial commitment is, but briefly: it allows you to commit to a polynomial and then later prove its evaluation at some point . Check my post on Kate polynomial commitments for more on polynomial commitment schemes.
How does that translate to the inner product argument though? First, let’s see our polynomial as a vector of coefficients:
Then notice that
And here’s our inner product again.
The idea behind Bootleproof-type of inner product argument
The inner product argument protocol I’m about to explain was invented by Bootle et al. It was later optimized in the Bulletproof paper (hence why we unofficially call the first paper bootleproof), and then some more in the Halo paper. It’s the later optimization that I’ll explain here.
A naive approach
So before I get into the weeds, what’s the high-level? Well first, what’s a naive way to prove that we know the pre-image of a hash , the vector , such that ? We could just reveal and let anyone verify that indeed, hashing it gives out , and that it also verifies the equation .
Obliviously, we have to reveal itself, which is not great. But we’ll deal with that later, trust me. What we want to tackle first here is the proof size, which is the size of the vector . Can we do better?
Reducing the problem to a smaller problem to prove
The inner product argument reduces the opening proof by using an intermediate reduction proof:
Where the size of is half the size of , and as such the final opening proof () is half the size of our naive approach.
The reduction proof is where most of the magic happens, and this reduction can be applied many times ( times to be exact) to get a final opening proof of size 1. Of course the entire proof is not just the final opening proof of size 1, but all the elements involved in the reduction proofs. It can still be much smaller than the original proof of size .
So most of the proof size comes from the multiple reduction subproofs that you’ll end up creating on the way. Our proof is really a collection of miniproofs or subproofs.
One last thing before we get started: Pedersen hashing and commitments
To understand the protocol, you need to understand commitments. I’ve used hashing so far, but hashing with a hash function like SHA-3 is not great as it has no convenient mathematical structure. We need algebraic commitments, which will allow us to prove things on the committed value without revealing the value committed. Usually what we want is some homomorphic property that will allow us to either add commitments together or/and multiply them together.
For now, let’s see a simple non-hiding commitment: a Pedersen hash. To commit to a single value simply compute:
where the discrete logarithm of is unknown. To open the commitment, simply reveal the value .
We can also perform multi-commitments with Pedersen hashing. For a vector of values , compute:
where each is distinct and has an unknown discrete logarithm as well. I’ll often shorten the last formula as the inner product for and . To reveal a commitment, simply reveal the values .
Pedersen hashing allow commitents that are non-hiding, but binding, as you can’t open them to a different value than the originally committed one. And as you can see, adding the commitment of and gives us the commitment of :
which will be handy in our inner product argument protocol
The protocol
Set up
Here are the settings of our protocol. Known only to the prover, is the secret vector
The rest is known to both:
- , a basis for Pedersen hashing
- , the commitment of
- , the powers of some value such that
- the result of the inner product
For the sake of simplicity, let’s pretend that this is our problem, and we just want to halve the size of our secret vector before revealing it. As such, we will only perform a single round of reduction. But you can also think of this step as being already the reduction of another problem twice as large.
We can picture the protocol as follows:
- The prover first sends a commitment to the polynomial .
- The verifier sends a point , asking for the value . To help the prover perform a proof of correct evaluation, they also send a random challenge . (NOTE: The verifier sends the random challenge ONLY AFTER they receive the )
- The prover sends the result of the evaluation, , as well as a proof.
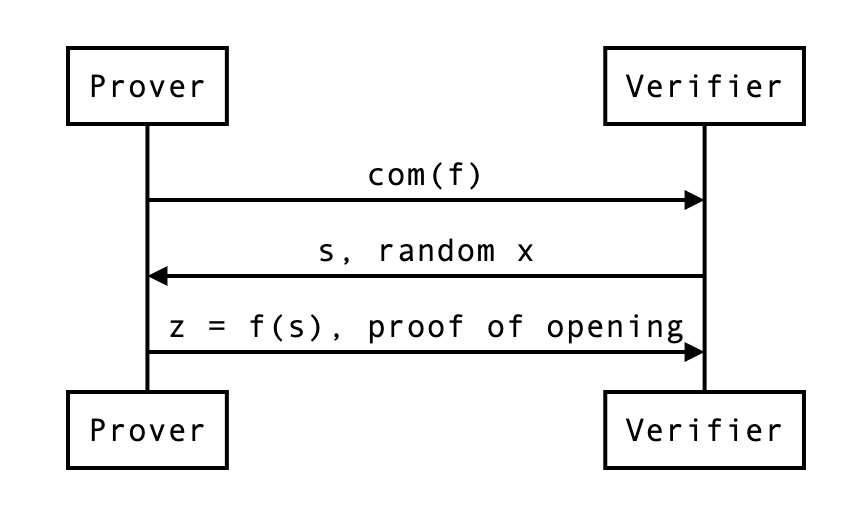
Does that make sense? Of course what’s interesting to us is the proof, and how the prover uses that random .
Reduced problem
First, the prover cuts everything in half. Then they use to construct linear combinations of these cuts:
This is how the problem is reduced to .
At this point, the prover can send , , and and the verifier can check if indeed . But that wouldn’t make much sense would it? Here we also want:
- a proof that proving that statement is the same as proving the previous statement ()
- a way for the verifier to compute and and (the new commitment) by themselves.
The actual proof
The verifier can compute as they have everything they need to do so.
What about , the commitment of which uses the new basis. It should be the following value:
So to compute this new commitment, the verifier needs:
- the previous commitment , which they already have
- some powers of , which they can compute
- two curve points and , which the prover will have to provide to them
What about ? Recall:
So the new inner product should be:
Similarly to , the verifier can recompute from the previous value and two scalar values and which the prover needs to provide.
So in the end, the proof has become:
- the vector which is half the size of
- the curve points (around two field elements, if compressed)
- the scalar values
We can update our previous diagram:
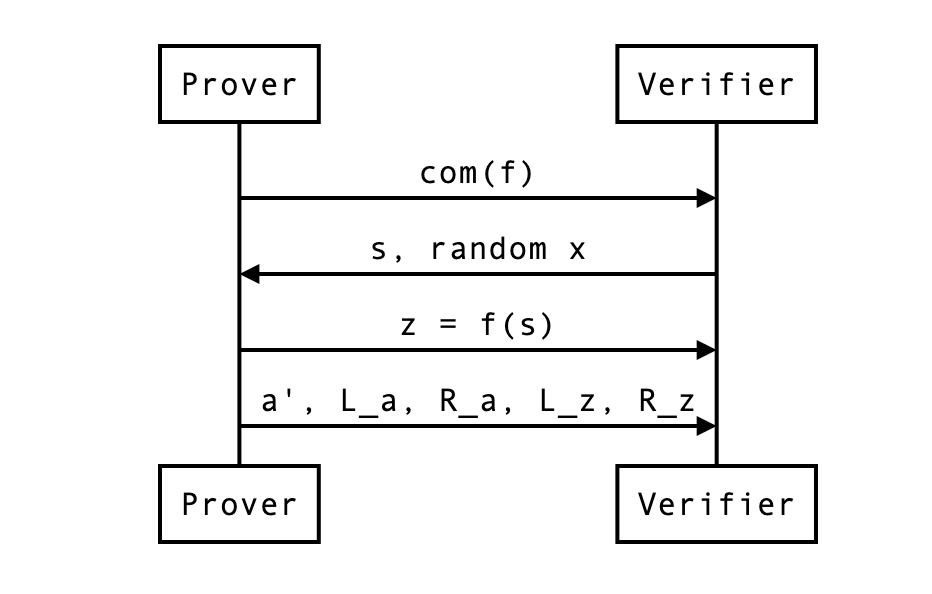
In our example, the naive proof was to reveal which was 4 field elements. We are now revealing instead 2 + 2 + 2 = 6 field elements. This is not great, but if was much larger (let’s say 128), the reduction in half would still be of 64 + 2 + 2 = 68 field elements. Not bad no? We can do better though…
The HALO optimization
The HALO optimization is similar to the bulletproof optimization, but it further reduces the size of our proof, so I’ll explain that directly.
With the HALO optimization, the prover translates the problem into the following:
This is simply a commitment of and .
A naive proof is to reveal and let the verifier check that it is a valid opening of the following commitment. Then, that commitment will be reduced recursively to commitments of the same form.
The whole point is that the reduction proofs will be smaller than our previous bootleproof-inspired protocol.
How does the reduction proof work? Notice that this is the new commitment:
This is simply from copy/pasting the equations from the previous section. This can be further reduced to:
And now you see that the verifier now only needs, in addition to , two curve points (~ 2 field elements):
this is in contrast to the 4 field elements per reduction needed without this optimization. Much better right?
At the end of a round (or the protocol) the verifier can compute the expected commitment as such:
and open it by computing the following and checking it is indeed equal to :
For this, the verifier needs to recompute and by themselves, which they can as they have all the necessary information. We can update our previous diagram:
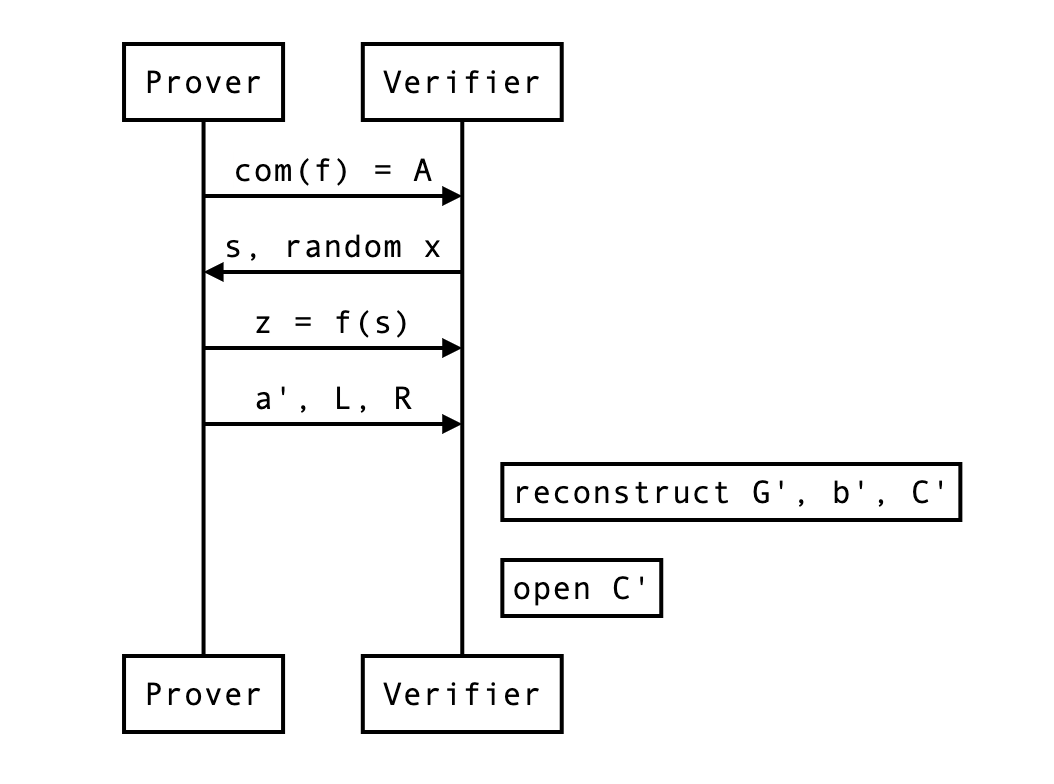
What about zero-knowledge?
Didn’t we forget something? Oh right, we’re sending in clear, a single element that will leak some information about the original vector (as it is a linear combination of that original vector).
The simple solution is to alter our pedersen commitment to make it hiding on top of being binding:
where H is another generator we don’t know the discrete logarithm of, and is a random scalar value generated by the prover to blind the commitment.
But wait, each and also leaks some! As they are also made from the original secret vector . Remember, No worries, we can perform the same treatment on that curve point and blind it like so:
In order to open the final commitment, the verifier first recomputes the expected commitment as before:
then use and the final blinding value sent by the prover (and composed of and all the rounds’ and ), as well as reconstructed and to open the commitment:
with being equal to something like
At this point, the protocol requires the sender to send:
- 2 curve points and per rounds
- 1 scalar value for the final opening
- 1 blinding (scalar) value for the final opening
But wait… one last thing. In this protocol the prover is revealing , and even if they were not, by revealing they might allow someone to recompute … The HALO paper contains a generalized Schnorr protocol to open the commitment without revealing nor .

from Vanishree:
- So in general the more data we send the more randomness we need to ensure the private aspects are hidden, right
- The randomness in a commitment is because we are sending the commitment elements
- The random elements mixed with the polynomial (in the new zkpm technique) is because we send evaluations of the polynomial at zeta and zeta omega later
- Zk in Schnorr opening is because we reveal the opening values
where can I find a proof? perhaps appendix C of https://eprint.iacr.org/2017/1066.pdf
The real protocol, and a note on non-interactivity
Finally, we can look at what the real protocol end up looking at with rounds of reduction followed by a commitment opening.
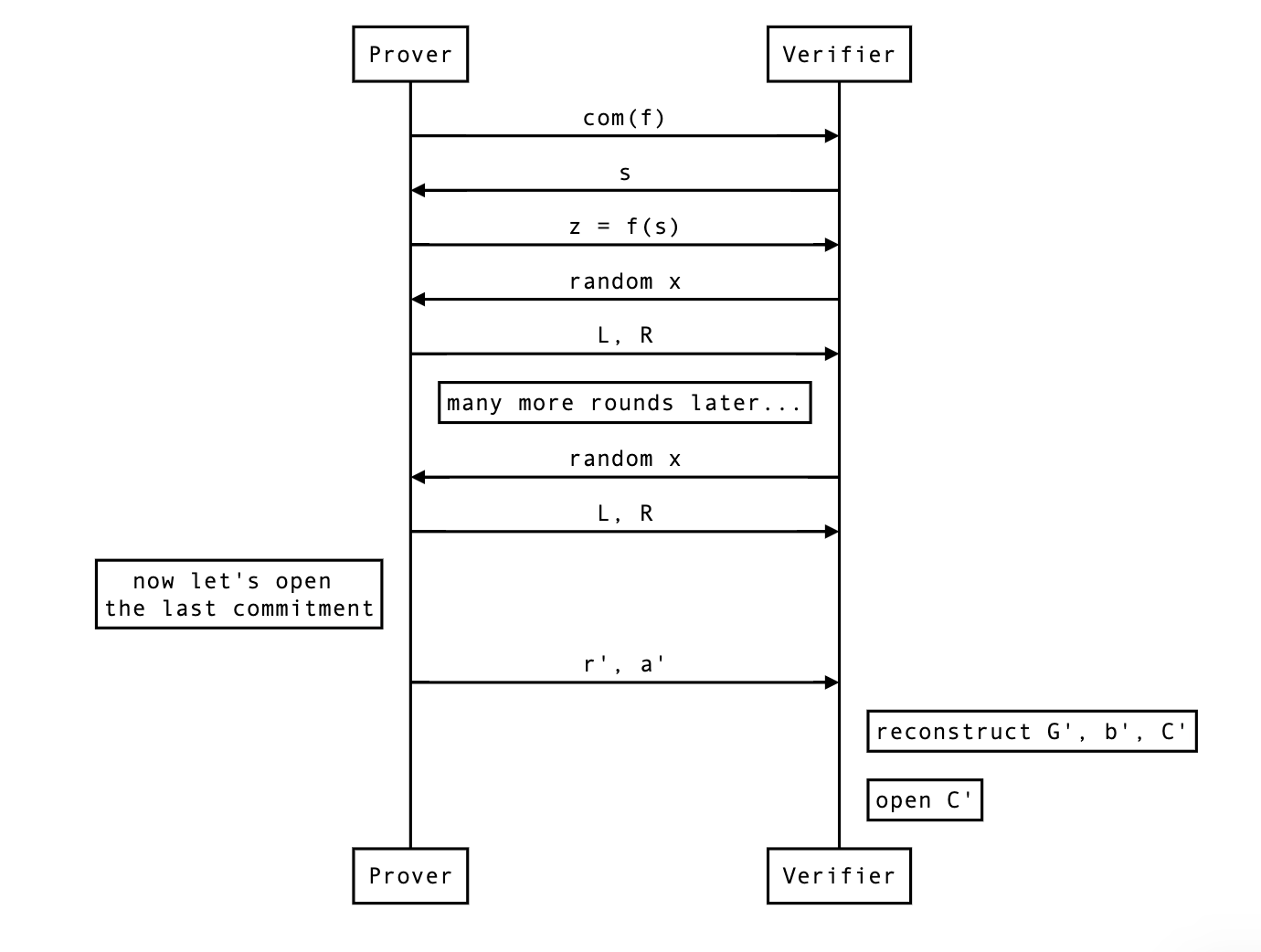
So far the protocol was interactive, but you can make it non-interactive by simply using the Fiat-Shamir transformation. That’s all I’ll say about that.