# Accumulation
Introduction
The trick below was originally described in Halo, however we are going to base this post on the abstraction of “accumulation schemes” described by Bünz, Chiesa, Mishra and Spooner in Proof-Carrying Data from Accumulation Schemes, in particular the scheme in Appendix A. 2.
Relevant resources include:
- Proof-Carrying Data from Accumulation Schemes by Benedikt Bünz, Alessandro Chiesa, Pratyush Mishra and Nicholas Spooner.
- Recursive Proof Composition without a Trusted Setup (Halo) by Sean Bowe, Jack Grigg and Daira Hopwood.
This page describes the most relevant parts of these papers and how it is implemented in Pickles/Kimchi. It is not meant to document the low-level details of the code in Pickles, but to describe what the code aims to do, allowing someone reviewing / working on this part of the codebase to gain context.
Interactive Reductions Between Relations
The easiest way to understand “accumulation schemes” is as a set of interactive reductions between relations. An interactive reduction proceeds as follows:
- The prover/verifier starts with some statement , the prover additionally holds .
- They then run some protocol between them.
- After which, they both obtain and the prover obtains
Pictorially:
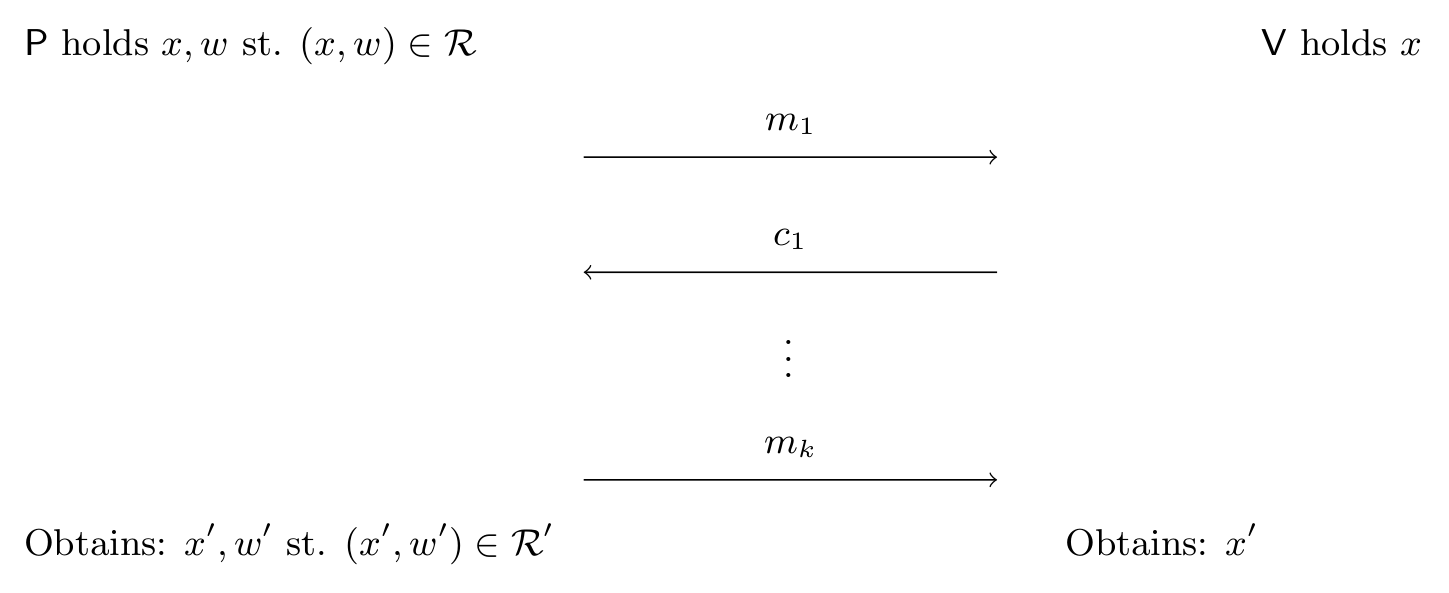
With the security/completeness guarantee that:
Except with negligible probability.
In other words: we have reduced membership of to membership of using interaction between the parties: unlike a classical Karp-Levin reduction the soundness/completeness may rely on random coins and multiple rounds. Foreshadowing here is a diagram/overview of the reductions (the relations will be described as we go) used in Pickles:

As you can see from Fig. 2, we have a cycle of reductions (following the arrows) e.g. we can reduce a relation “” to itself by applying all 4 reductions. This may seem useless: why reduce a relation to itself?
However the crucial point is the “in-degree” (e.g. n-to-1) of these reductions: take a look at the diagram and note that any number of instances can be reduced to a single instance! This instance can then be converted to a single by applying the reductions (moving “around the diagram” by running one protocol after the other):
Note: There are many examples of interactive reductions, an example familiar to the reader is PlonK itself: which reduces circuit-satisfiability ( is the public inputs and is the wire assignments) to openings of polynomial commitments ( are polynomial commitments and evaluation points, is the opening of the commitment).
More Theory/Reflections about Interactive Reductions (click to expand)
As noted in Compressed -Protocol Theory and Practical Application to Plug & Play Secure Algorithmics every Proof-of-Knowledge (PoK) with -rounds for a relation can instead be seen as a reduction to some relation with rounds as follows:
- Letting be the view of the verifier.
- be a ’th-round message which could make the verifier accept.
Hence the relation is the set of verifier views (except for the last round) and the last missing message which would make the verifier accept if sent.
This simple, yet beautiful, observation turns out to be extremely useful: rather than explicitly sending the last-round message (which may be large/take the verifier a long time to check), the prover can instead prove that he knows a last-round message which would make the verifier accept, after all, sending the witness is a particularly simple/inefficient PoK for .
The reductions in this document are all of this form (including the folding argument): receiving/verifying the last-round message would require too many resources (time/communication) of the verifier, hence we instead replace it with yet another reduction to yet another language (e.g. where the witness is now half the size).
Hence we end up with a chain of reductions: going from the languages of the last-round messages. An “accumulation scheme” is just an example of such a chain of reductions which happens to be a cycle. Meaning the language is “self-reducing” via a series of interactive reductions.
A Note On Fiat-Shamir: All the protocols described here are public coin and hence in implementation the Fiat-Shamir transform is applied to avoid interaction: the verifiers challenges are sampled using a hash function (e.g. Poseidon) modelled as a reprogrammable random oracle.
Polynomial Commitment Openings
Recall that the polynomial commitment scheme (PCS) in Kimchi is just the trivial scheme based on Pedersen commitments. For Kimchi we are interested in “accumulation for the language () of polynomial commitment openings”, meaning that:
Where is a list of coefficients for a polynomial .
This is the language we are interested in reducing: providing a trivial proof, i.e. sending requires linear communication and time of the verifier, we want a poly-log verifier. The communication complexity will be solved by a well-known folding argument, however to reduce computation we are going to need the “Halo trick”.
First a reduction from PCS to an inner product relation.
Reduction 1:
Formally the relation of the inner product argument is:
where are of length .
We can reduce to with as follows:
- Define . Because was a satisfying witness to , we have . The prover sends .
- The verifier adds the evaluation to the commitment “in a new coordinate” as follows:
- Verifier picks and sends to the prover.
- Prover/Verifier updates
Intuitively we sample a fresh to avoid a malicious prover “putting something in the -position”, because he must send before seeing , hence he would need to guess before-hand. If the prover is honest, we should have a commitment of the form:
Note: In some variants of this reduction is chosen as for a constant where by the verifier, this also works, however we (in Kimchi) simply hash to the curve to sample .
Reduction 2 (Incremental Step):
Note: The folding argument described below is the particular variant implemented in Kimchi, although some of the variable names are different.
The folding argument reduces a inner product with (a power of two) coefficients to an inner product relation with coefficients. To see how it works let us rewrite the inner product in terms of a first and second part:
Where and , similarly for .
Now consider a “randomized version” with a challenge of this inner product:
Additional intuition: How do you arrive at the expression above? (click to expand)
The trick is to ensure that ends up in the same power of .
The particular expression above is not special and arguably not the most elegant: simpler alternatives can easily be found and the inversion can be avoided, e.g. by instead using: Which will have the same overall effect of isolating the interesting term (this time as the -coefficient). The particular variant above can be found in e.g. Compressed -Protocol Theory and Practical Application to Plug & Play Secure Algorithmics and proving extraction is somewhat easier than the variant used in Kimchi.
The term we care about (underlined in magenta) is , the other two terms are cross-term garbage. The solution is to let the prover provide commitments to the cross terms to “correct” this randomized splitting of the inner product before seeing : the prover commits to the three terms (one of which is already provided) and the verifier computes a commitment to the new randomized inner product. i.e.
The prover sends commitment to the cross terms and :
The verifier samples and updates the commitment as:
The final observation in the folding argument is simply that:
where is the new witness.
Hence we can replace occurrences of by , with this look at the green term:
By defining . We also rewrite the blue term in terms of similarly:
By defining . In summary by computing:
We obtain a new instance of the inner product relation (of half the size):
At this point the prover could send , to the verifier who could verify the claim:
- Computing from and
- Computing from , and (obtained from the preceeding round)
- Checking
This would require half as much communication as the naive proof. A modest improvement…
However, we can iteratively apply this transformation until we reach an instance of constant size:
Reduction 2 (Full):
That the process above can simply be applied again to the new instance as well. By doing so times the total communication is brought down to -elements until the instance consists of at which point the prover simply provides the witness .
Because we need to refer to the terms in the intermediate reductions we let , , be the , , vectors respectively after recursive applications, with , , being the original instance. We will drop the vector arrow for (similarly, for ), since the last step vector has size , so we refer to this single value instead. We denote by the challenge of the ’th application.
Reduction 3:
While the proof for above has -size, the verifiers time-complexity is :
- Computing from using takes .
- Computing from using takes .
The rest of the verifiers computation is only , namely computing:
- Sampling all the challenges .
- Computing for every
However, upon inspection, the more pessimistic claim that computing takes turns out to be false:
Claim: Define , then for all . Therefore, can be evaluated in .
Proof: This can be verified by looking at the expansion of . Define to be the coefficients of , that is . Then the claim is equivalent to . Let denote the th bit in the bit-decomposition of the index and observe that: Now, compare this with how a th element of is constructed: Recalling that , it is easy to see that this generalizes exactly to the expression for that we derived later, which concludes that evaluation through is correct.
Finally, regarding evaluation complexity, it is clear that can be evaluated in time as a product of factors. This concludes the proof.
The “Halo Trick”
The “Halo trick” resides in observing that this is also the case for : since it is folded the same way as . It is not hard to convince one-self (using the same type of argument as above) that:
Where is the coefficients of (like is the coefficients of ), i.e.
For notational convince (and to emphasise that they are 1 dimensional vectors), define/replace:
With this we define the “accumulator language” which states that “” was computed correctly:
Note: since there is no witness for this relation anyone can verify the relation (in time) by simply computing in linear time. Instances are also small: the size is dominated by which is .
In The Code: in the Kimchi code is called prev_challenges and is called comm,
all defined in the RecursionChallenge struct.
Now, using the new notation rewrite as:
Note: It is the same relation, we just replaced some names (, ) and simplified a bit: inner products between 1-dimensional vectors are just multiplications.
We now have all the components to reduce (with no soundness error) as follows:
- Prover sends to the verifier.
- Verifier does:
- Compute
- Checks
- Output
Note: The above can be optimized, in particular there is no need for the prover to send .
Reduction 4:
Tying the final knot in the diagram.
The expensive part in checking consists in computing given the describing : first expanding into , then computing the MSM. However, by observing that is actually a polynomial commitment to , which we can evaluate at any point using operations, we arrive at a simple strategy for reducing any number of such claims to a single polynomial commitment opening:
- Prover sends to the verifier.
- Verifier samples , and computes:
Alternatively:
And outputs the following claim:
i.e. the polynomial commitment opens to at . The prover has the witness:
Why is this a sound reduction: if one of the does not commit to then they disagree except on at most points, hence with probability . Taking a union bound over all terms leads to soundness error – negligible.
The reduction above requires operations and operations.
Support for Arbitrary Polynomial Relations
Additional polynomial commitments (i.e. from PlonK) can be added to the randomized sums above and opened at as well: in which case the prover proves the claimed openings at before sampling the challenge .
This is done in Kimchi/Pickles: the and above is the same as in the Kimchi code.
The combined (including both the evaluations and polynomial commitment openings at and ) is called combined_inner_product in Kimchi.

This instance reduced back into a single instance, which is included with the proof.
Multiple Accumulators (PCD Case)
From the section above it may seem like there is always going to be a single instance, this is indeed the case if the proof only verifies a single proof, “Incremental Verifiable Computation” (IVC) in the literature. If the proof verifies multiple proofs, “Proof-Carrying Data” (PCD), then there will be multiple accumulators: every “input proof” includes an accumulator ( instance), all these are combined into the new (single) instance included in the new proof: this way, if one of the original proofs included an invalid accumulator and therefore did not verify, the new proof will also include an invalid accumulator and not verify with overwhelming probability.

Note that the new proof contains the (single) accumulator of each “input” proof, even though the proofs themselves are part of the witness: this is because verifying each input proof results in an accumulator (which could then be checked directly – however this is expensive): the “result” of verifying a proof is an accumulator (instance of ) – which can be verified directly or further “accumulated”.
These accumulators are the RecursionChallenge structs included in a Kimchi proof.
The verifier check the PlonK proof (which proves accumulation for each “input proof”), this results in some number of polynomial relations,
these are combined with the accumulators for the “input” proofs to produce the new accumulator.
Accumulation Verifier
The section above implicitly describes the work the verifier must do, but for the sake of completeness let us explicitly describe what the verifier must do to verify a Fiat-Shamir compiled proof of the transformations above. This constitutes “the accumulation” verifier which must be implemented “in-circuit” (in addition to the “Kimchi verifier”), the section below also describes how to incorporate the additional evaluation point (“the step”, used by Kimchi to enforce constraints between adjacent rows). Let be the challenge space (128-bit GLV decomposed challenges):
-
PlonK verifier on outputs polynomial relations (in Purple in Fig. 4).
-
Checking and polynomial relations (from PlonK) to (the dotted arrows):
-
Sample (evaluation point) using the Poseidon sponge.
-
Read claimed evaluations at and (
PointEvaluations). -
Sample (commitment combination challenge,
polyscale) using the Poseidon sponge. -
Sample (evaluation combination challenge,
evalscale) using the Poseidon sponge.- The notation is consistent with the Plonk paper where recombines commitments and recombines evaluations
-
Compute with from:
- (
RecursionChallenge.comm) - Polynomial commitments from PlonK (
ProverCommitments)
- (
-
Compute (part of
combined_inner_product) with from:- The evaluations of
- Polynomial openings from PlonK (
ProofEvaluations) at
-
Compute (part of
combined_inner_product) with from:- The evaluations of
- Polynomial openings from PlonK (
ProofEvaluations) at
At this point we have two PCS claims, these are combined in the next transform.
At this point we have two claims: These are combined using a random linear combination with in the inner product argument (see [Different functionalities](../plonk/inner_product_api.html) for details).
-
-
Checking .
- Sample using the Poseidon sponge: hash to curve.
- Compute .
- Update .
-
Checking :
Check the correctness of the folding argument, for every :- Receive (see the vector
OpeningProof.lrin Kimchi). - Sample using the Poseidon sponge.
- Compute (using GLV endomorphism)
(Note: to avoid the inversion the element is witnessed and the verifier checks . To understand why computing the field inversion would be expensive see deferred computation)
- Receive (see the vector
-
Checking
- Receive form the prover.
- Define from (folding challenges, computed above).
- Compute a combined evaluation of the IPA challenge polynomial on two points:
- Computationally, is obtained inside bulletproof folding procedure, by folding the vector such that using the same standard bulletproof challenges that constitute . This is a -recombined evaluation point. The equality is by linearity of IPA recombination.
- Compute , this works since: See Different functionalities for more details or the relevant code.
- Compute (i.e. st. )
Note that the accumulator verifier must be proven (in addition to the Kimchi/PlonK verifier) for each input proof.
No Cycles of Curves?
Note that the “cycles of curves” (e.g. Pasta cycle) does not show up in this part of the code:
a separate accumulator is needed for each curve and the final verifier must check both accumulators to deem the combined recursive proof valid.
This takes the form of passthough data in pickles.
Note however, that the accumulation verifier makes use of both -operations and -operations, therefore it (like the Kimchi verifier) also requires deferred computation.