Maller’s optimization for Kimchi
This document proposes a protocol change for kimchi.
What is Maller’s optimization?
See the section on Maller’s optimization for background.
Overview
We want the verifier to form commitment to the following polynomial:
They could do this like so:
Since they already know , they can produce , the only thing they need is . So the protocol looks like that:
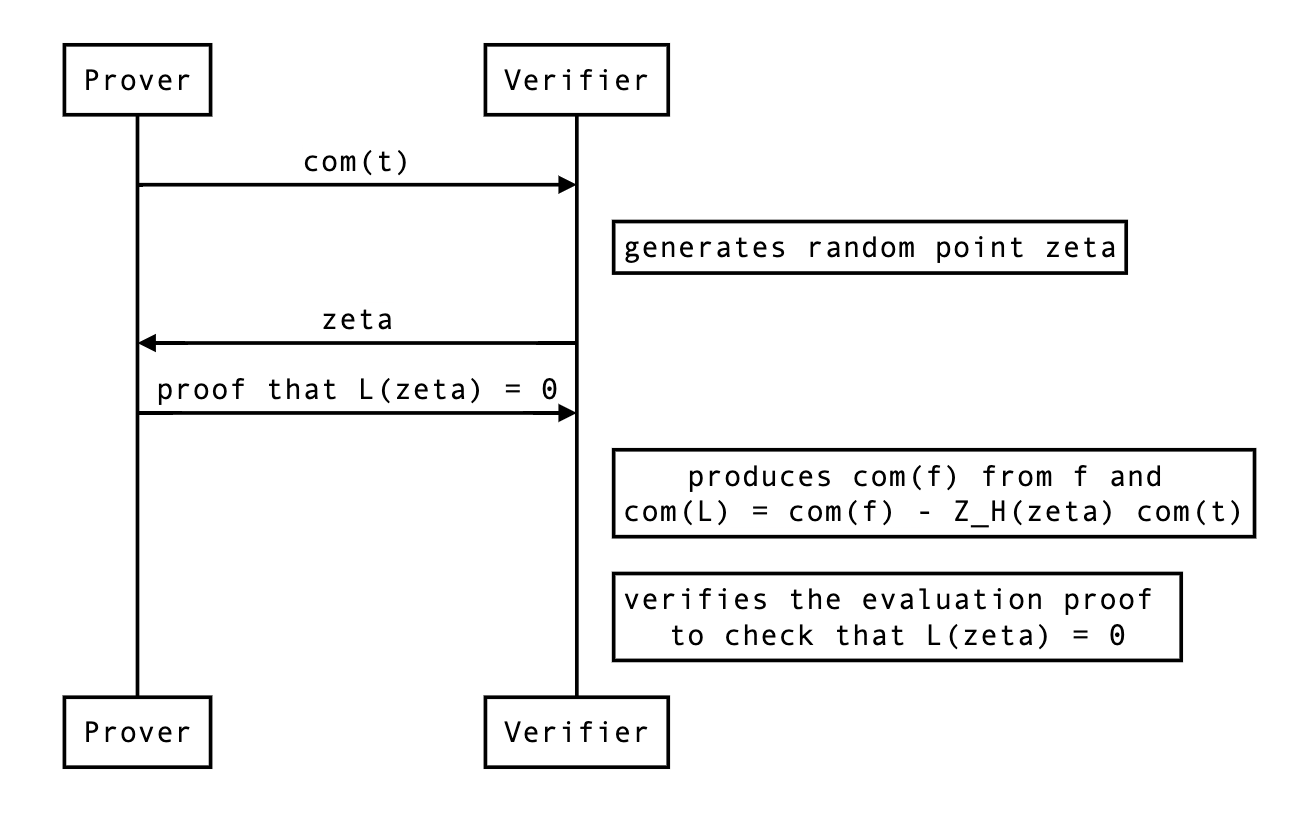
In the rest of this document, we review the details and considerations needed to implement this change in kimchi.
How to deal with a chunked ?
There’s one challenge that prevents us from directly using this approach: is typically sent and received in several commitments (called chunks or segments throughout the codebase). As is the largest polynomial, usually exceeding the size of the SRS (which is by default set to be the size of the domain).
The verifier side
Thus, the verifier will have to produce split commitments of and combine them with powers of to verify an evaluation proof. Let’s define as:
where every is of degree at most. Then we have that
Which the verifier can’t produce because of the powers of , but we can linearize it as we already know which we’re going to evaluate that polynomial with:
The prover side
This means that the prover will produce evaluation proofs on the following linearized polynomial:
which is the same as only if evaluated at . As the previous section pointed out, we will need and .
Evaluation proof and blinding factors
To create an evaluation proof, the prover also needs to produce the blinding factor associated with the chunked commitment of:
To compute it, there are two rules to follow:
- when two commitment are added together, their associated blinding factors get added as well:
- when scaling a commitment, its blinding factor gets scaled too:
As such, if we know and , we can compute:
The prover knows the blinding factor of the commitment to , as they committed to it. But what about ? They never commit to it really, and the verifier recreates it from scratch using:
- The commitments we sent them. In the linearization process, the verifier actually gets rid of most prover commitments, except for the commitment to the last sigma commitment . (TODO: link to the relevant part in the spec) As this commitment is public, it is not blinded.
- The public commitments. Think commitment to selector polynomials or the public input polynomial. These commitments are not blinded, and thus do not impact the calculation of the blinding factor.
- The evaluations we sent them. Instead of using commitments to the wires when recreating , the verifier uses the (verified) evaluations of these in . If we scale our commitment with any of these scalars, we will have to do the same with .
Thus, the blinding factor of is .
The evaluation of
The prover actually does not send a commitment to the full polynomial. As described in the last check section. The verifier will have to compute the evaluation of because it won’t be zero. It should be equal to the following:
Because we use the inner product polynomial commitment, we also need:
Notice the . That evaluation must be sent as part of the proof as well.
The actual protocol changes
Now here’s how we need to modify the current protocol:
- The evaluations (and their corresponding evaluation proofs) don’t have to be part of the protocol anymore.
- The prover must still send the chunked commitments to .
- The prover must create a linearized polynomial by creating a linearized polynomial and a linearized polynomial and computing:
- While the verifier can compute the evaluation of by themselves, they don’t know the evaluation of , so the prover needs to send that.
- The verifier must recreate , the commitment to , themselves so that they can verify the evaluation proofs of both and .
- The evaluation of must be absorbed in both sponges (Fq and Fr).
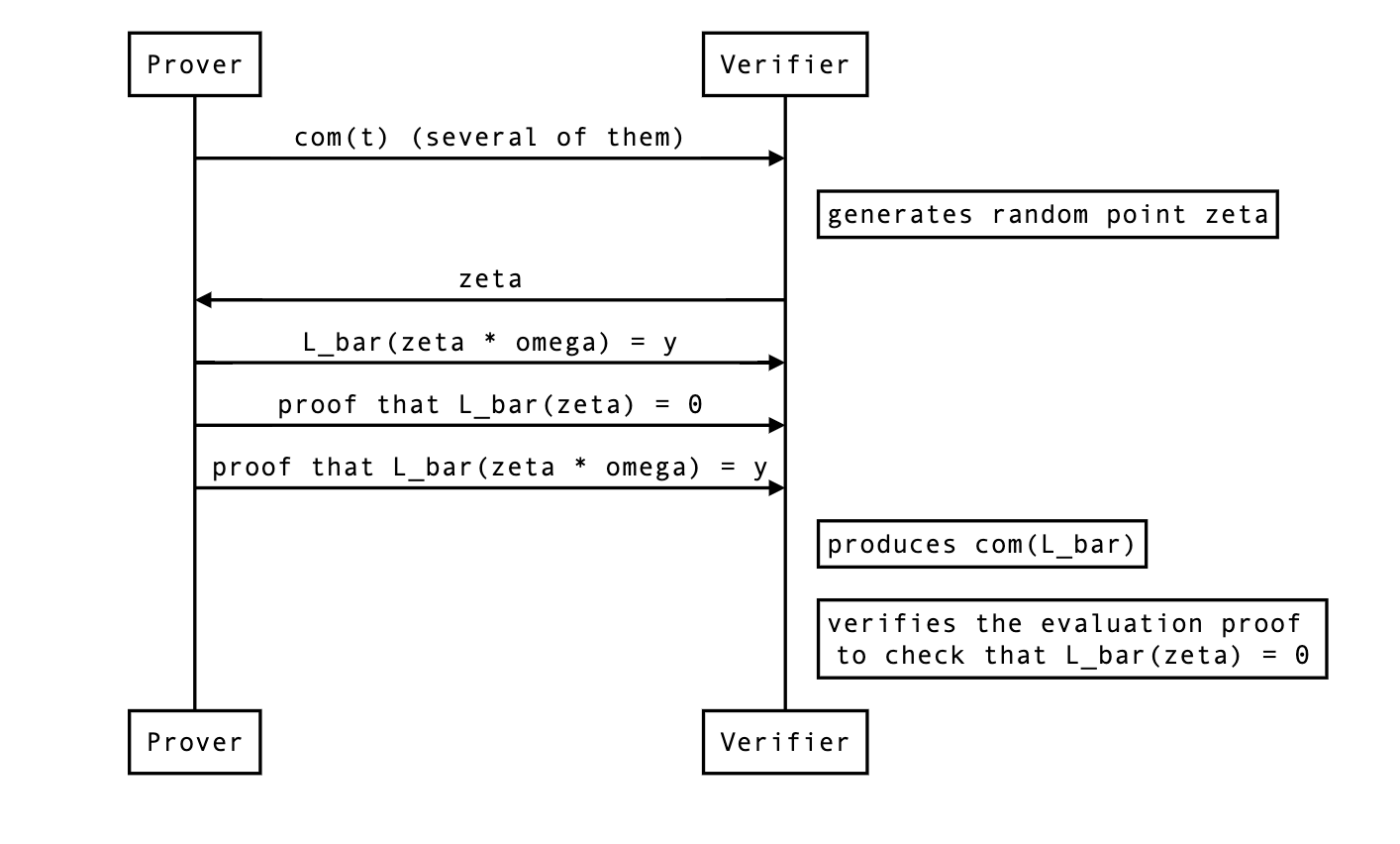
The proposal is implemented in #150 with the following details:
- the polynomial is called
ft. - the evaluation of is called
ft_eval0. - the evaluation is called
ft_eval1.